
Abstract
We investigated methods to execute LLM and multimodal workloads on‑prem, with bounded memory/compute and strict privacy constraints. Our work focuses on: (i) auto‑adaptive execution—dynamic selection of model, precision, and routing given a hardware/latency/energy budget; (ii) signed incremental updates for reproducible deployment and rollback; and (iii) evaluation protocols that jointly measure quality, latency, and energy. This note outlines our setting, methods, and planned releases.
1. Motivation
Most AI stacks assume elastic cloud resources and permissive data flows. We study the opposite regime: a single workstation‑class GPU, intermittent networks, and data that must not leave the premises. The challenge is to preserve task quality while keeping latency and energy bounded and the system fully auditable.
2. Problem statement
Our main constraints for this project will be the price, the quality of the output, the size of the hardware setup, the plug-and-play installation for our clients, and the ability to implement agentic architectures on the server.
3. System overview
- Planner. Observes hardware/load, selects plan
p: model family, 4/5/8‑bit precision, adapters, context strategy, retrieval/tool calls. - Signed artefacts. Models, adapters, tokenizers, and configs are shipped as signed bundles. Updates are deltas; rollback is constant‑time.
- Traceable runtime. Each run stores hashes, plan, seeds, wall‑clock metrics. Reports are reproducible offline.
- No‑egress policy. Inputs/outputs and telemetry remain local; external calls are disabled by default.
4. Methods (current)
- Budget‑aware quantization. Map
H, Bto feasible precisions and KV‑cache policies; learn a routing prior from historicalE. - Selective distillation. For target tasks, train small adapters that recover accuracy lost by quantization.
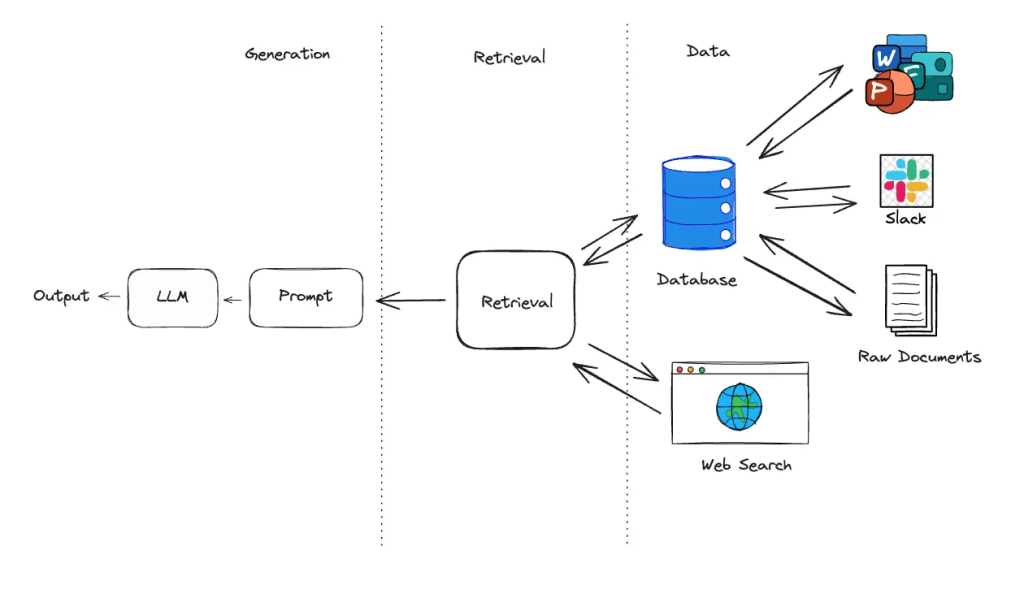
- Context optimisation. Lightweight RAG with domain caches; strict filters to minimise token traffic.
- Update pipeline. Artefact → SBOM → sign → verify at load; each request references an immutable manifest.
- Measurement. On‑device energy via power telemetry; latency at token and end‑to‑end levels; quality via public benches plus domain test sets.
5. Evaluation protocol
- Public benches. MMLU, AIME‑style reasoning, code tasks, summarisation QA.
- Operational sets. Anonymised domain prompts; we will release generators and scoring scripts.
- Reports. Per task:
Q, latency, energy, andE; per hardware: mean/variance across seeds; full manifests for replication. - Ablations. Model family, precision, cache policy, adapter on/off, RAG on/off.
6. Preliminary status
- Auto‑adaptive planner and signed‑update chain implemented; initial deployments run on a single‑GPU local server.
- Early results: task‑specific adapters can recover a significant fraction of accuracy at 4–5‑bit with practical latency on commodity GPUs.
- We will release full reports after partner pilots; meanwhile we plan to publish methods and measurement code.
7. Limitations & risks
- Distribution shift. Adapter gains may not transfer across domains; we mitigate via validation suites and fast rollback.
- Hardware diversity. Telemetry fidelity varies across GPUs/CPUs; manifests include drivers and firmware.
- Security. Signed packages reduce supply‑chain risk but require disciplined key management; we document procedures.
8. Roadmap
- Release v1 of the planner, signed‑artefact specification, and measurement toolkit.
- Publish the first benchmark report (quality / latency / energy) on a constrained single‑GPU setup.
- Extend to multimodal (text–image) under the same budgets.
- Formalise governance and audit procedures for regulated environments.


Leave a comment