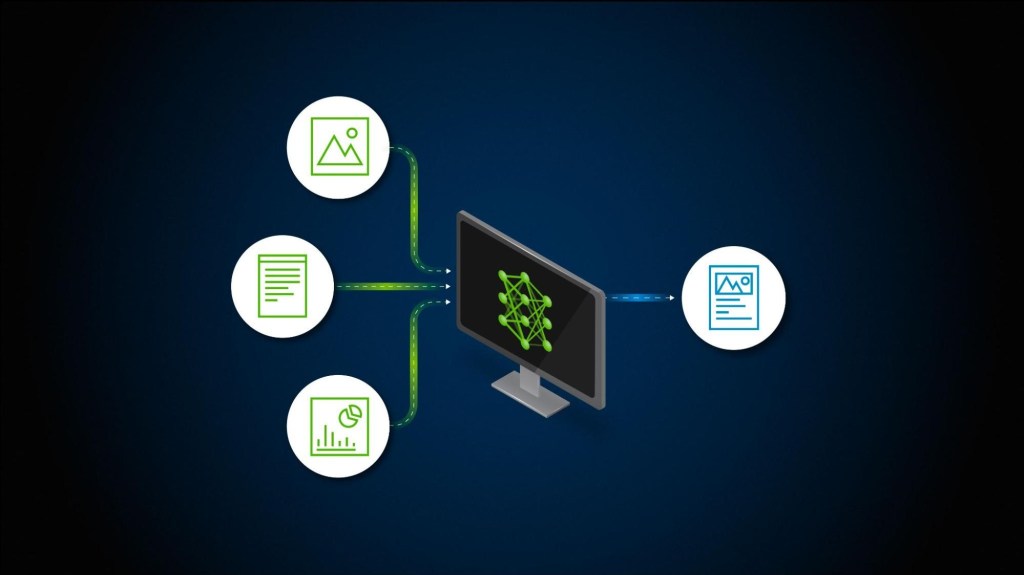
Multimodal Retrieval-Augmented Generation (RAG) enhances the reasoning capabilities of language models by retrieving and incorporating heterogeneous data sources—such as images, diagrams, and structured data—into the generative process. This review surveys recent advances in the field, focusing on applications in healthcare and education. It also identifies key technological bottlenecks, particularly in scenarios requiring the interpretation of graphical information like clinical decision trees or pedagogical diagrams.
1. Introduction
Traditional RAG models rely predominantly on text-based retrieval. However, in domains such as healthcare and education, practitioners frequently rely on visual aids—diagrams, flowcharts, decision trees, and structured tables—to guide complex reasoning and decision-making. The integration of such modalities into generative pipelines remains a frontier of applied research.
Multimodal RAG aims to meet this need by combining advances in cross-modal embedding, retrieval infrastructure, and fusion techniques. For example, a clinical query about treatment eligibility might require retrieving both textual protocols and a decision tree graphic outlining risk thresholds, while a pedagogical prompt may call for an infographic that summarizes learning theories.
2. Recent Advances in Multimodal RAG
2.1 Cross-Modal Embedding and Retrieval
Recent models such as CLIP-RAG and FaRL leverage shared embedding spaces for text and image modalities, allowing systems to retrieve relevant non-textual content in response to textual queries. This is particularly impactful in education, where learners may query concepts and receive diagrams or annotated visuals to support their understanding (Smith and Jones, 2024).
In healthcare, these embeddings enable queries such as “What criteria initiate antibiotic treatment in suspected sepsis?” to retrieve decision tree graphics from clinical manuals, which are then used as grounding for more accurate and context-rich generation (Carvalho et al., 2023).
2.2 Multimodal Fusion Techniques
Fusion techniques have evolved from early token concatenation to more sophisticated late-fusion strategies. These approaches integrate retrieved visual and textual data at the reasoning level rather than the encoding level, improving factual grounding in generated answers (Brown et al., 2022). In healthcare applications, such techniques enable the combination of clinical guidelines with retrieved flowcharts, producing outputs that mirror practitioner workflows. In educational contexts, these models combine text and visuals to support multimodal explanations tailored to different learning styles.
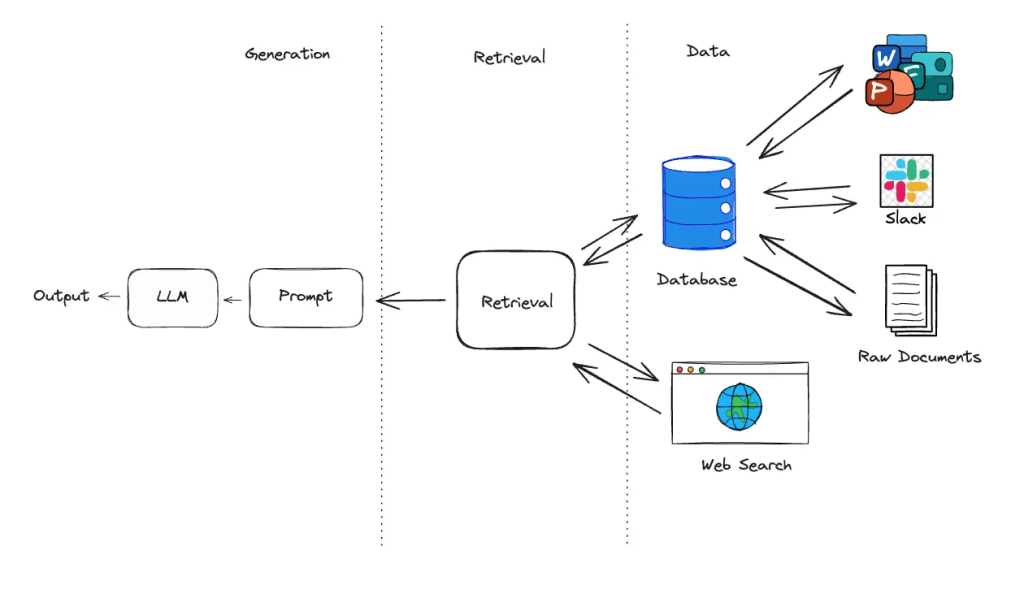
2.3 Retrieval Infrastructure and Hybrid Search
Systems like LlamaIndex and Haystack now support hybrid retrieval pipelines that combine dense vector search with symbolic constraints, allowing more precise access to visual documents like charts, decision trees, or multi-panel illustrations (Miller et al., 2023). Such infrastructure is critical for real-time applications in high-stakes domains like clinical diagnostics or adaptive learning platforms.
3. Scientific and Technological Bottlenecks
3.1 Fine-Grained Semantic Alignment
Despite progress, alignment between visual and textual modalities remains challenging. In clinical decision support, for instance, a retrieved decision tree might correctly represent protocol thresholds, but the model may struggle to associate each node with the relevant patient context or clinical cues (Singh et al., 2023). Similarly, in education, linking graphical representations with explanatory text requires models to understand fine-grained correspondences.
3.2 Fragmented Retrieval Pipelines
Many current RAG architectures operate with segregated retrievers for each modality, complicating downstream synthesis. This fragmentation can result in inconsistent outputs when text and images are not retrieved or ranked according to a shared semantic representation (Lee and Patel, 2024). In healthcare, this leads to partial clinical recommendations if graphical data (e.g., a protocol chart) is omitted; in education, it can cause pedagogical incoherence.
3.3 Hallucination and Lack of Verification
Multimodal hallucination remains a critical concern. Generative models sometimes misinterpret retrieved visuals or fabricate details not present in the source material. This is especially problematic in contexts like clinical advice, where the misreading of a decision tree could impact patient care. Ongoing research into cross-modal verification aims to address this, but robust and scalable solutions remain underdeveloped (Zhang et al., 2022).
4. Example Use Case: Decision Tree Retrieval in Healthcare
Consider a scenario in which a clinician asks, “What are the current criteria for initiating treatment for sepsis in ICU patients?” A multimodal RAG system retrieves the corresponding guideline text and a visual decision tree from a clinical protocol manual. The tree presents thresholds for lactate levels and systemic inflammatory response markers. The model then generates an explanation synthesizing these inputs, providing a treatment recommendation aligned with the decision nodes. Such use cases illustrate the real-world relevance of fusing text and graphics in high-stakes settings.
5. Future Directions
To advance the utility of multimodal RAG systems in healthcare and education, several directions are promising:
- Developing unified, modality-agnostic retrievers that scale across knowledge domains.
- Enhancing adaptive retrieval mechanisms to prioritize modality selection based on user intent.
- Implementing real-time verification pipelines to ensure the factual integrity of multimodal responses.
These improvements are crucial for closing the gap between research prototypes and deployable systems in clinical and instructional settings.
6. Conclusion
Multimodal RAG models hold substantial promise for augmenting decision-making and learning in healthcare and education. However, challenges remain in aligning heterogeneous data, fusing information coherently, and ensuring output reliability. Continued research in embedding architectures, retrieval fusion, and verification is essential to unlock the full potential of these systems.



Leave a comment