In January 2024, OpenAI’s CEO Sam Altman claimed that one day we will witness for the first time a one-person billion-dollar company, by leveraging the power of generative AI.
This shows his vision of the role of AI in the coming years: a single person making high-level decisions, while the entirety of the work is managed by LLM-based AI agents, replacing thousands of employees, from the engineer to the legal advisor or the manager.
One of the strong implications from this scenario is that AI agents would have an enormous amount of responsibility and autonomy in the decision-making process, with the need to bypass the typical hierarchical structure we have today in order to take all types of decisions, from company-scale ones to team level or even single worker day-to-day decisions with lower impact.
Whether this claim is realistic or not, we are clearly seeing effort going in that direction, with more and more companies trying to integrate AI tools to increase productivity, and consequently profit.
Despite the impressive performance of today’s LLMs, we remain highly cautious about granting AI significant autonomy. As a CEO, would you really entrust top-level decision-making power to an employee who isn’t able to count the number of ‘r’s in the word ‘strawberry’?
The core issue lies in the nature of their capabilities: while LLMs can provide highly valuable information and outperform humans in specific tasks, they are also prone to errors that are shockingly simple for a human brain to avoid. This highlights the fundamental differences in how AI and humans operate, questioning whether the term intelligence as we’ve traditionally used it to describe living beings, can truly apply to these systems.
We currently lack a reliable way to assess the accuracy of their outputs without investing significant human effort into verification. This creates a dilemma: while granting these systems greater power and autonomy can unlock much more efficiency compared to human work, it also increases the risk of catastrophic errors with strong consequences.
Is AI really making more errors than humans?
Before the surge in generative AI, almost all models that have significantly impacted human productivity were designed for highly specialized tasks. This contrasts with human intelligence, which is inherently broad and general in nature. When focusing on isolated tasks, however, AI has demonstrated its ability to match or even surpass human performance across many domains.
| Task | Year | Model | Details |
|---|---|---|---|
| Chess | 1997 | Deep Blue (IBM) | Deep Blue defeated world champion Garry Kasparov in a six-game match by a score of 3.5–2.5, becoming the first computer to beat a reigning chess world champion under tournament conditions. |
| Face Recognition | 2014 | DeepFace (Facebook) | DeepFace achieved an accuracy of 97.35% on the Labeled Faces in the Wild (LFW) dataset, almost reaching the average human accuracy of 97.53%. |
| Image Recognition | 2015 | ResNet (Microsoft Research) | ResNet achieved a lower error rate (3.57%) than humans (5.1%) on the ImageNet classification task, marking the first time AI surpassed human accuracy in large-scale image recognition. |
| Speech Recognition | 2017 | Microsoft Conversational Speech Recognition System | This system achieved a word error rate of 5.1%, matching human performance in transcribing conversational speech from the Switchboard dataset. |
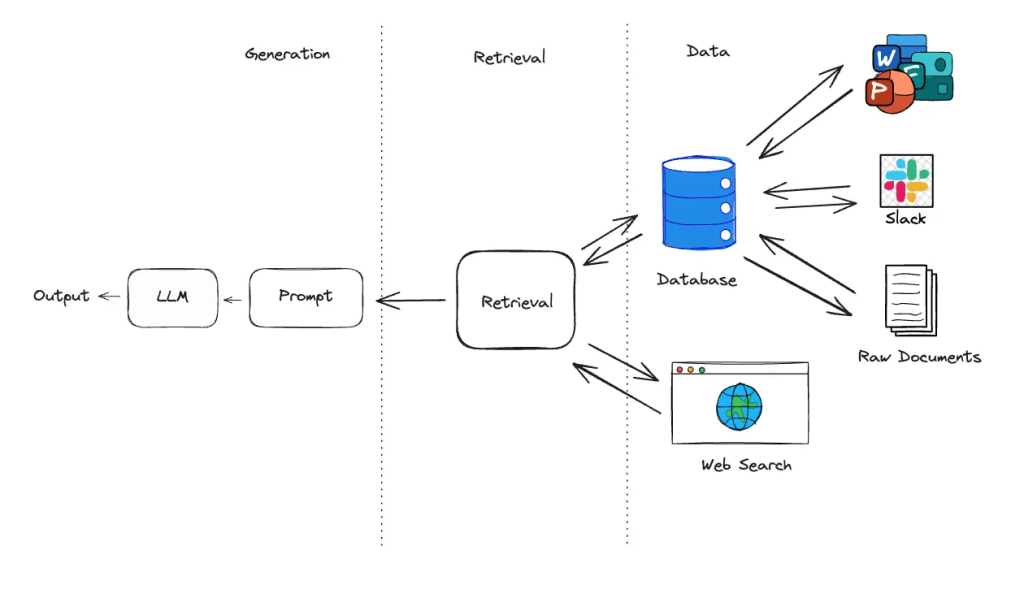
However, for general tasks requiring basic physics and logic knowledge that humans acquire through vision at a very early age, the state-of-the-art AI models are still struggling for that. A good example is the ARC-AGI benchmark that was made to evaluate the efficiency of AI reasoning and pattern recognition on unknown tasks.
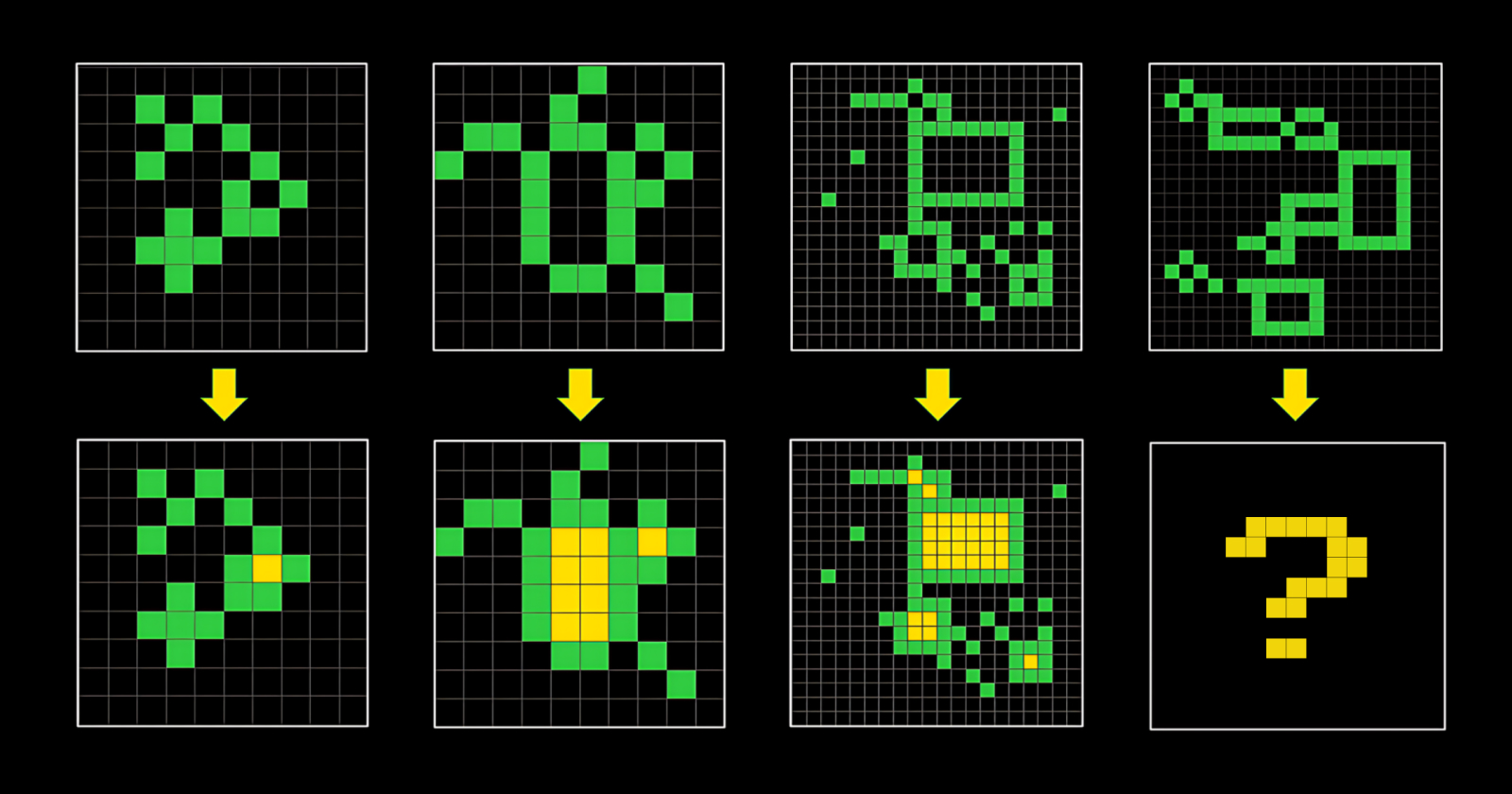
The ARC-AGI benchmark tests abstract reasoning and pattern recognition on unknown tasks. While humans achieve an average accuracy of 75%, most LLMs score significantly lower (e.g., GPT-4o at 50%). OpenAI’s O3 model is the only exception, reaching 85% accuracy.
A possible explanation for this struggle is that while LLMs excel at memorizing patterns from vast amounts of textual data, they have significant difficulty applying logical principles and generalizing learned concepts to unseen problems.
Abstract reasoning tasks, such as those presented in the ARC-AGI benchmark, require spatial representation and logical inference capabilities. Humans intuitively grasp underlying patterns and generalize them to novel situations, sometimes even without needing to explicitly formalize rules.
This limitation becomes particularly evident when generative AI models attempt to perform tasks involving spatial logic or structured rules, such as playing chess. A purely text-based generative AI model struggles significantly to infer the spatial logic governing chess piece movements, inevitably making illegal moves and failing to complete a coherent game, let alone defeating a human opponent.
A core challenge for current LLMs is their exclusive reliance on text-based training data. Without explicit grounding in spatial or sensory experiences, it is unclear whether these models can develop robust internal representations of space or physical logic. This leads the ongoing debate in the AI research community regarding the feasibility of achieving human-like intelligence through text-only learning:
- Yann LeCun argues that true human-like intelligence requires sensory grounding beyond text alone. He recently stated at the NVIDIA GTC 2025: “I am not interested anymore in LLMs. They are just token generators and those are limited because tokens are in discrete space. I am more interested in next-gen model architectures, that should be able to do 4 things: understand physical world, have persistent memory and ultimately be more capable to plan and reason”. According to LeCun, incorporating sensory modalities such as vision input is essential for developing meaningful spatial reasoning capabilities, and a true ‘world model’, meaning a fundamental understand of the world and basic physic intuitions, that the humans all obtain at a young age, mostly through vision and hearing.
- In contrast, Ilya Sutskever, co-founder of OpenAI, believes that “text is a projection of the world,” suggesting that by simply predicting subsequent tokens in text sequences, LLMs implicitly learn about various aspects of reality—including human interactions, motivations, and even abstract concepts. In this view, a sufficiently advanced language model could potentially develop an internal world model, extracting meaningful spatial and logical representations solely from textual information.
This raises the question to what extent we can really trust AIs to make important decisions.
Different Autonomy Stages
Currently, the most reliable approach to integrating AI into company workflows involves maintaining human involvement in the decision-making process. Across industries, different levels of AI autonomy are implemented depending on context and risk tolerance.
AI autonomy can be categorized into the following stages:
Human in the Loop
In this stage, AI acts primarily as a supportive tool to enhance human productivity. The AI system is designed to closely follow human vision and problem-solving skills, with limited independent decision-making capabilities. Responsibility for the success or failure of tasks remains entirely with the human operator.
Applications: Coding assistants, content generation tools, data analysis tools.
Human on the Loop
In this semi-autonomous stage, AI systems can independently make decisions within clearly defined boundaries but remain under human supervision. Humans monitor the system’s performance and decision-making processes, intervening only when necessary or when encountering edge cases and anomalies.
Applications: Semi-autonomous vehicles, AI-powered customer support systems.
Human out of the Loop
This stage aligns closely with Sam Altman’s vision of a “one-person billion-dollar company,” where AI operates independently without regular human intervention for most tasks. Humans provide only high-level guidance and occasional strategic feedback, relying on advanced AI alignment to handle day-to-day operations autonomously. At this level, decisions are made entirely by AI systems, as human intervention would often be inefficient due to complexity and scale.
Applications: Fully autonomous vehicles, general-purpose multi-domain AI agents.
Even if we were able to reach the performance in generative AI models needed for this final autonomy stage, a huge challenge that would not necessarily be solved simultaneously is AI alignment.
AI alignment
AI alignment defines the process of encoding the fundamental human values, goals and ethical considerations, in the AI models to ensure that that even future AI models surpassing human intelligence remain safe, trustworthy, and beneficial to humanity.
A common illustration is the scenario of asking a superintelligent AI how to solve global warming. An easy solution could be to eliminate humanity altogether, as humans are the primary contributors to climate change. This solution obviously violates core human values. While we could explicitly integrate the preservation of human life as a constraint for the AI when solving this particular problem, this is only one very specific example. It is completely unrealistic to rigorously define every possible rule that we want the AI to respect for each goal we assign it. In contrast, AI alignment aims to inherently embed these fundamental principles into the AI’s reasoning process, so that we wouldn’t need to explicitly specify constraints such as preserving human life.
AI Alignment through Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) is a foundational method for aligning AI systems with human values. This approach fine-tunes pre-trained models by leveraging human feedback to train a reward model, which then guides the reinforcement learning process.
Specifically, for each prompt in the training dataset, the model generates two or more responses. A human evaluator ranks these responses based on their quality or alignment with desired outcomes. These rankings are used to train the reward model, which learns to predict a score reflecting how well a response aligns with human preferences. The reward model is then used to guide the fine-tuning of the large language model (LLM) through reinforcement learning, optimizing the LLM to produce outputs that maximize the reward.
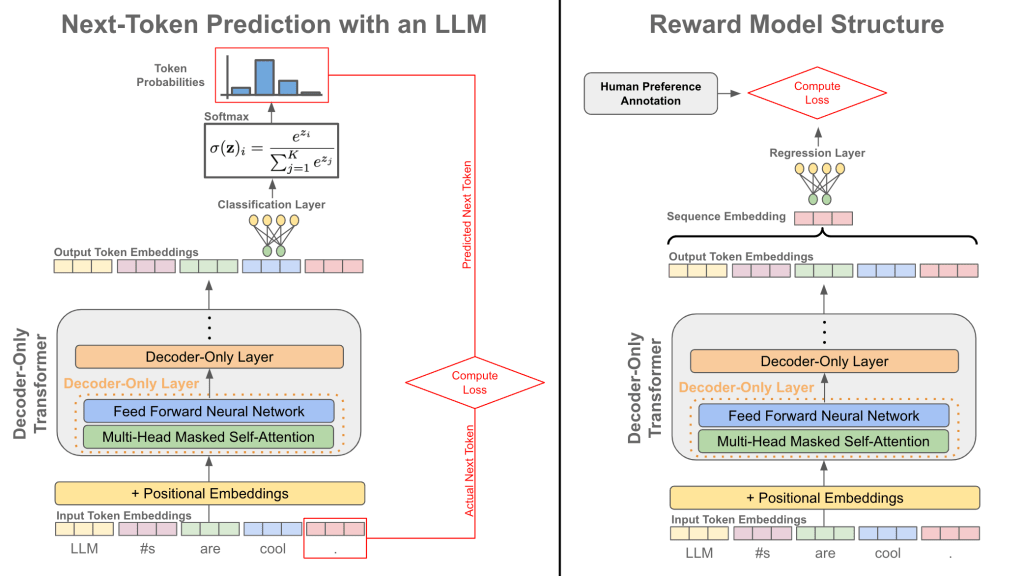
Source: Cameron R. Wolfe
While effective, RLHF faces challenges such as scalability and reliance on costly human annotations. For example, Llama-2 required more than 1M human feedback anotations. To address these limitations, an alternative method called Reinforcement Learning from AI Feedback (RLAIF) has emerged. As demonstrated in research by Lee et al., RLAIF achieves performance comparable to RLHF by using feedback generated by another AI model instead of humans. This feedback is guided by a predefined set of ethical principles, often referred to as a “constitution,” which ensures alignment with safety and ethical standards.
RLAIF draws inspiration from Anthropic’s “Constitutional AI,” which uses human made rules and guidelines so that AI can train other AIs by following these instructions. By automating the feedback process, RLAIF mitigates the scalability issues inherent in RLHF and reduces subjectivity in evaluations. However, it introduces its own challenges, such as potential biases in the AI feedback model, which may propagate into the trained system. RLHF remains widely used in practice due to its direct incorporation of human judgment, which can capture nuanced preferences and ethical considerations more effectively than current automated methods.

Source: Lee et al.
Conclusion
The vision of a one-person billion-dollar company underscores the transformative potential of AI, but it also serves as a reminder of the responsibility required to ensure its safe and ethical use. AI should not aim to replace human judgment but rather to complement and enhance it, operating within carefully constructed boundaries that prioritize trust, accountability, and alignment with human values. As we witness the rapid technological advancement in LLMs and other generative AI models, investing in robust and ethical frameworks will be crucial to give enough trust to these models for them to have a game changing value in our society and economy.
Reviewed and published by Simon Heilles.



Leave a comment