Introduction
Neural networks are powerful tools for processing sequential and structured data, but how they internally store and retrieve information remains a fascinating open question. This research project aims to investigate how deeply connected neural networks encode and retain information from text inputs, while optimizing network architectures for efficiency. Below, we outline the goals, methodology, and potential implications of this work.
Research Objectives
- Memory Storage Analysis:
How do neural networks represent sequential text data in their hidden layers? Specifically, how is information distributed across neurons, and how does connectivity influence retention? - Architecture Comparison:
Compare different neural network types (e.g., RNNs, LSTMs, Transformers) to determine which requires the fewest neurons to reliably store input data. - Topology Optimization:
Enhance neural network architectures by refining layer connections, activation functions, or neuron behaviors to improve memory efficiency.
Methodology
1. Input Encoding
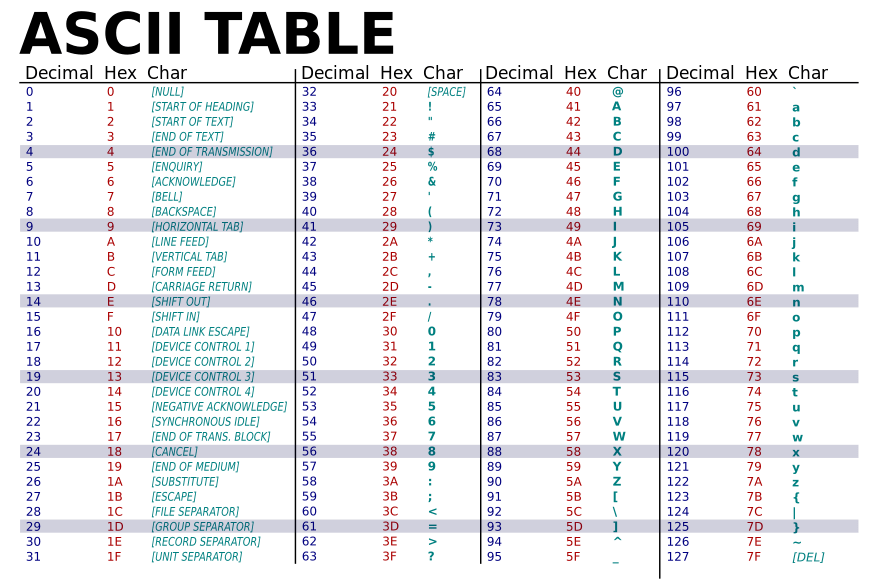
- Text-to-Float Conversion: Each ASCII character (0–255) is mapped to a unique floating-point value (e.g., scaled to [0, 1]).
- Sequential Processing: Text is fed one character at a time into 256 input neurons. For example, the word “hello” would be processed as 5 sequential inputs.
- Illustration: ASCII Encoding Example
2. Network Architectures Under Study
- Recurrent Neural Networks (RNNs): Process sequences with loops to retain memory.
- Long Short-Term Memory (LSTM): Improved memory via gated cells.
- Transformers: Use self-attention for parallelized sequence modeling.
- Dense Feedforward Networks: Fully connected layers with no recurrence.
3. Metrics
- Minimal Neuron Count: The smallest number of neurons required to reconstruct input text from hidden states.
- Reconstruction Accuracy: Compare outputs to original inputs after training.
How Information is Stored in Neural Networks
Neural networks store information through synaptic weights and activation patterns. In sequential models like RNNs, hidden states act as memory buffers. However, the exact mechanism varies:
- RNNs: Compress history into hidden states, but suffer from vanishing gradients.
- LSTMs: Use forget/input gates to manage long-term dependencies.
- Transformers: Store context via attention weights across tokens.
Optimizing Network Topology
To minimize neurons while preserving memory:
- Pruning: Remove redundant connections.
- Dynamic Activation Functions: Use context-aware activations (e.g., SIREN).
- Sparse Connectivity: Prioritize critical pathways.
- Hybrid Architectures: Combine strengths of RNNs and attention.
Academic References
- Memory in RNNs:
- Hochreiter & Schmidhuber (1997). LSTM Paper
- Attention Mechanisms:
- Vaswani et al. (2017). Transformers Paper
- Neural Network Efficiency:
- Frankle & Carbin (2019). The Lottery Ticket Hypothesis
Implications
- AI Interpretability: Understanding memory storage could demystify “black-box” models.
- Efficient Models: Optimized topologies reduce computational costs for edge devices.
- Neuroscience Parallels: Insights into biological neural memory systems.
Conclusion
This research bridges theoretical neuroscience and machine learning, offering a systematic approach to studying memory in neural networks. By quantifying memory efficiency and refining architectures, we aim to build models that are both compact and powerful.
Connect with the author: guillaume@denemlabs.com
Reviewed and published by Simon Heilles.



{kind=link}
Leave a comment